
瑞芯微RK3588是国产SoC领域的标杆,凭借其先进的8nm工艺与八核64位的高性能架构,被广泛公认为边缘计算的“全能王者”。它集成了超强的影像处理能力,支持8K视频编解码与多屏异显。在实际应用中,它深度覆盖了高端边缘服务器、医疗影像辅助、智能工业检测以及智慧政务等对功耗控制和多媒体性能有极高要求的场景。
然而,随着大语言模型(LLM)时代的到来,RK3588在商业落地中面临着显著的痛点:尽管其原生NPU具备6TOPS算力,但在运行如Qwen3-8B等动辄数十亿参数的大模型时,其算力密度与内存带宽便面临性能瓶颈。此外,对于开发者而言,在边缘端从零开始搭建复杂的驱动环境、解决不同Python版本的依赖冲突,往往存在极高的技术门槛和时间成本。
芯动力科技通过“硬核补强+标准SOP”完美解决了这些痛点。首先,芯动力科技M.2智能加速卡以即插即用的方式直接补齐了RK3588在重度推理上的算力短板,形成了CPU+GPU协同加速的配套模式——RK3588发挥其CPU在系统调度与通用计算方面的优势,而芯动力则通过专用GPU加速卡提供高性能AI推理算力。其次,芯动力科技发布了面向该平台的大语言模型(LLM)适配标准作业程序(SOP),为开发者提供更易部署的边缘AI加速方案,实现更稳定、低延迟的本地化AI推理能力,这种本地化推理方案不仅解决了算力焦虑,更确保了医疗、政务等行业对数据安全与隐私的核心诉求。

AzureEdge SR8-HM边缘服务器(搭载M.2智能加速卡的RK3588)
-
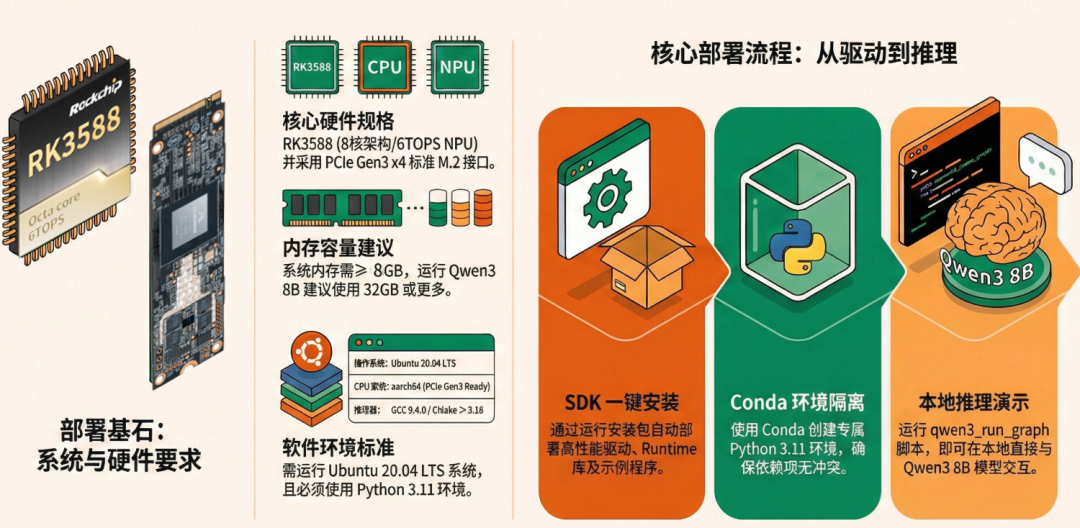
系统确认:确保环境满足Ubuntu 20.04、8 GB以上内存等基础要求。 -
SDK安装:通过芯动力科技SDK安装包,自动化完成驱动与运行时的配置。 -
环境隔离:使用Conda/Miniconda创建Python 3.11的独立环境,确保模型运行互不干扰。 -
模型启动:通过简单命令行即可快速加载并运行 Qwen 3B–8B及Llama 8B等同级模型。
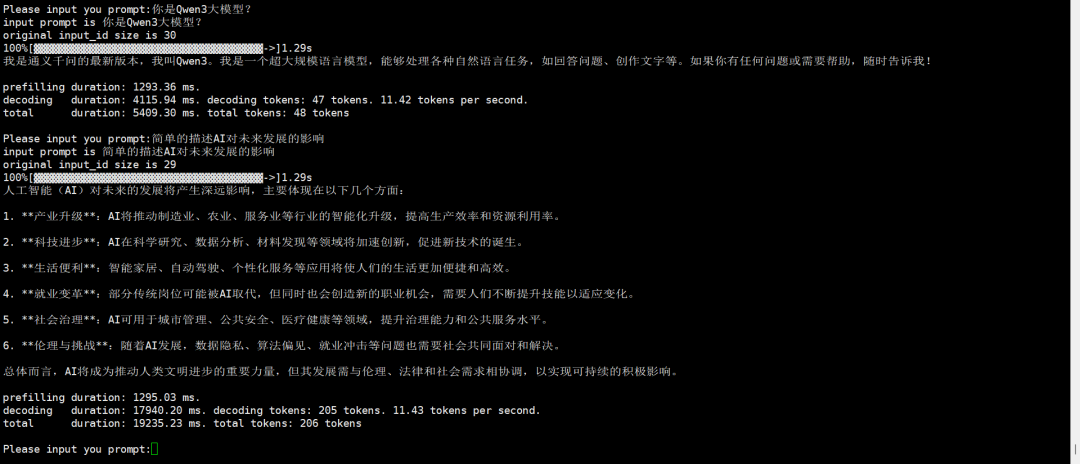
Qwen3-8B 推理实测:1.29s 极速响应与 12 tokens/s 流畅生成
这种方案不仅解决了数据隐私安全的核心诉求,更通过低功耗、高性能的本地算力,让AI NAS从简单的存储工具进化为企业的“私有智库”。AI NAS在商业场景中的成功应用,有力验证了芯动力科技直击边缘AI落地痛点的实战算力。
目前,芯动力已与众多行业客户深度合作,将“ 芯动力加速卡+RK3588 ”作为整体解决方案推向市场,形成了稳定、可复制的产品模式,广泛应用于智慧城市、工业质检等场景,实现从硬件到部署的全栈价值交付。
